Boulder Future Salon
 |
| The end of classical computer science is coming, and most of us are dinosaurs waiting for the meteor to hit, says Matt Welsh.
"I came of age in the 1980s, programming personal computers like the Commodore VIC-20 and Apple IIe at home. Going on to study computer science in college and ultimately getting a PhD at Berkeley, the bulk of my professional training was rooted in what I will call 'classical' CS: programming, algorithms, data structures, systems, programming languages." "When I was in college in the early '90s, we were still in the depth of the AI Winter, and AI as a field was likewise dominated by classical algorithms. In Dan Huttenlocher's PhD-level computer vision course in 1995 or so, we never once discussed anything resembling deep learning or neural networks--it was all classical algorithms like Canny edge detection, optical flow, and Hausdorff distances." "One thing that has not really changed is that computer science is taught as a discipline with data structures, algorithms, and programming at its core. I am going to be amazed if in 30 years, or even 10 years, we are still approaching CS in this way. Indeed, I think CS as a field is in for a pretty major upheaval that few of us are really prepared for." "I believe that the conventional idea of 'writing a program' is headed for extinction, and indeed, for all but very specialized applications, most software, as we know it, will be replaced by AI systems that are trained rather than programmed." "I'm not just talking about CoPilot replacing programmers. I'm talking about replacing the entire concept of writing programs with training models. In the future, CS students aren't going to need to learn such mundane skills as how to add a node to a binary tree or code in C++. That kind of education will be antiquated, like teaching engineering students how to use a slide rule." "The shift in focus from programs to models should be obvious to anyone who has read any modern machine learning papers. These papers barely mention the code or systems underlying their innovations; the building blocks of AI systems are much higher-level abstractions like attention layers, tokenizers, and datasets." This got me thinking: Over the last 20 years, I've been predicting AI would advance to the point where it could automate jobs, and it's looking more and more like I was fundamentally right about that, and all the people who poo-poo'd the idea over the years in coversations with me were wrong. But while I was right about that fundamental idea (and right that there wouldn't be "one AI in a box" that anyone could pull the plug on if something went wrong, but a diffusion of the technology around the world like every previous technology), I was wrong about how exactly it would play out. First I was wrong about the timescales: I thought it would be necessary to understand much more about how the brain works, and to work algorithms derived from neuroscience into AI models, and looking at the rate of advancement in neuroscience I predicted AI wouldn't be in its current state for a long time. While broad concepts like "neuron" and "attention" have been incorporated into AI, there are practically no specific algorithms that have been ported from brains to AI systems. Second, I was wrong about what order. I was wrong in thinking "routine" jobs would be automated first, and "creative" jobs last. It turns out that what matters is "mental" vs "physical". Computers can create visual art and music just by thinking very hard -- it's a purely "mental" activity, and computers can do all that thinking in bits and bytes. This has led me to ponder: What occupations require the greatest level of manual dexterity? Those should be the jobs safest from the AI revolution. The first that came to mind for me -- when I was trying to think of jobs that require an extreme level of physical dexterity and pay very highly -- was "surgeon". So I now predict "surgeon" will be the last job to get automated. If you're giving career advice to a young person (or you are a young person), the advice to give is: become a surgeon. Other occupations safe (for now) against automation, for the same reason would include "physical therapist", "dentist", "dental hygienist", "dental technician", "medical technician" (e.g. those people who customize prosthetics, orthodontic devices, and so on), and so on. "Nurse" who routinely does physical procedures like drawing blood. Continuing in the same vein but going outside the medical field (pun not intended but allowed to stand once recognized), I'd put "electronics technician". I don't think robots will be able to solder any time soon, or manipulate very small components, at least after the initial assembly is completed which does seem to be highly amenable to automation. But once electronic components fail, to the extent it falls on people to repair them, rather than throw them out and replace them (which admittedly happens a lot), humans aren't going to be replaced any time soon. Likewise "machinist" who works with small parts and tools. "Engineer" ought to be ok -- as long as they're mechanical engineers or civil engineers. Software engineers are in the crosshairs. What matters is whether physical manipulation is part of the job. "Construction worker" -- some jobs are high pay/high skill while others are low pay/low skill. Will be interesting to see what gets automated first and last in construction. Other "trade" jobs like "plumber", "electrician", "welder" -- probably safe for a long time. "Auto mechanic" -- probably one of the last jobs to be automated. The factory where the car is initially manufacturered, a very controlled environment, may be full of robots, but it's hard to see robots extending into the auto mechanic's shop where cars go when they break down. "Jewler" ought to be a safe job for a long time. "Watchmaker" (or "watch repairer") -- I'm still amazed people pay so much for old-fashioned mechanical watches. I guess the point is to be pieces of jewlry, so these essentially count as "jewler" jobs. "Tailor" and "dressmaker" and other jobs centered around sewing. "Hairstylist" / "barber" -- you probably won't be trusting a robot with scissors close to your head any time soon. "Chef", "baker", whatever the word is for "cake calligrapher". Years ago I thought we'd have automated kitchens at fast food restaurants by now but they are no where in sight. And nowhere near automating the kitchens of the fancy restaurants with the top chefs. Finally, let's revisit "artist". While "artist" is in the crosshairs of AI, some "artist" jobs are actually physical -- such as "sculptor" and "glassblower". These might be resistant to AI for a long time. Not sure how many sculptors and glassblowers the economy can support, though. Might be tough if all the other artists stampede into those occupations. While "musician" is totally in the crosshairs of AI, as we see, that applies only to musicians who make recorded music -- going "live" may be a way to escape the automation. No robots with the manual dexterity to play physical guitars, violins, etc, appear to be on the horizon. Maybe they can play drums? And finally for my last item: "Magician" is another live entertainment career that requires a lot of manual dexterity and that ought to be hard for a robot to replicate. For those of you looking for a career in entertainment. Not sure how many magicians the economy can support, though. |
| |
 |
| The Federal Trade Commission banned 'non-compete' agreements, to take effect in August. But it was only a 3-2 vote, and business groups are going to sue to maintain their ability to have employees sign non-compete contracts.
According to the article, business groups say non-compete agreements "protect trade secrets" and "promote competitiveness," while the FTC says banning non-competes would "increase worker earnings by up to $488 billion over the next decade and will lead to the creation of more than 8,500 new businesses each year." I wonder if that $488 billion can be realized over the next decade with artificial intelligence, not mentioned in the article, advancing so fast. Creation of 8,500 new businesses? The trend for decades is few businesses and more people working for large companies than small companies. I suppose you could blame non-compete agreements for that, in which case the claim that eliminating non-compete agreement creating new businesses would be true. Also when I hear "trade secrets," I think advanced technology, but the article claims Democrats claim non-compete agreements are used "even in lower-paying service industries such as fast food and retail." |
| |
 |
| "In defense of AI art".
YouTuber "LiquidZulu" makes a gigantic video aimed at responding once and for all to all possible arguments against AI art. His primary argument seems to me to be that AI art systems are learning art in a manner analogous to human artists -- by learning from examples from other artists -- and do not plagiarize because they do not copy exactly any artists' work. In contrast AI art systems are actually good at combining styles in new ways. Therefore, AI art generators are just as valid "artists" as any human artists. Artists have no right to government protection from getting their jobs get replaced by technology, he says, because nobody anywhere else in the economy has any right to government protection to getting their jobs replaced by technology. On the flip side, he thinks the ability of AI art generators to bring the ability to create art to the masses is a good thing that should be celebrated. Below-average artists have no right to deprive people of this ability to generate the art they like because those low-quality artists want to be paid. Apparently he considers himself an anarcho-capitalist (something he has in common with... nobody here?) and has has harsh words for people he considers neo-Luddites. He accuses artists complaining about AI art generators of being "elitist". |
| |
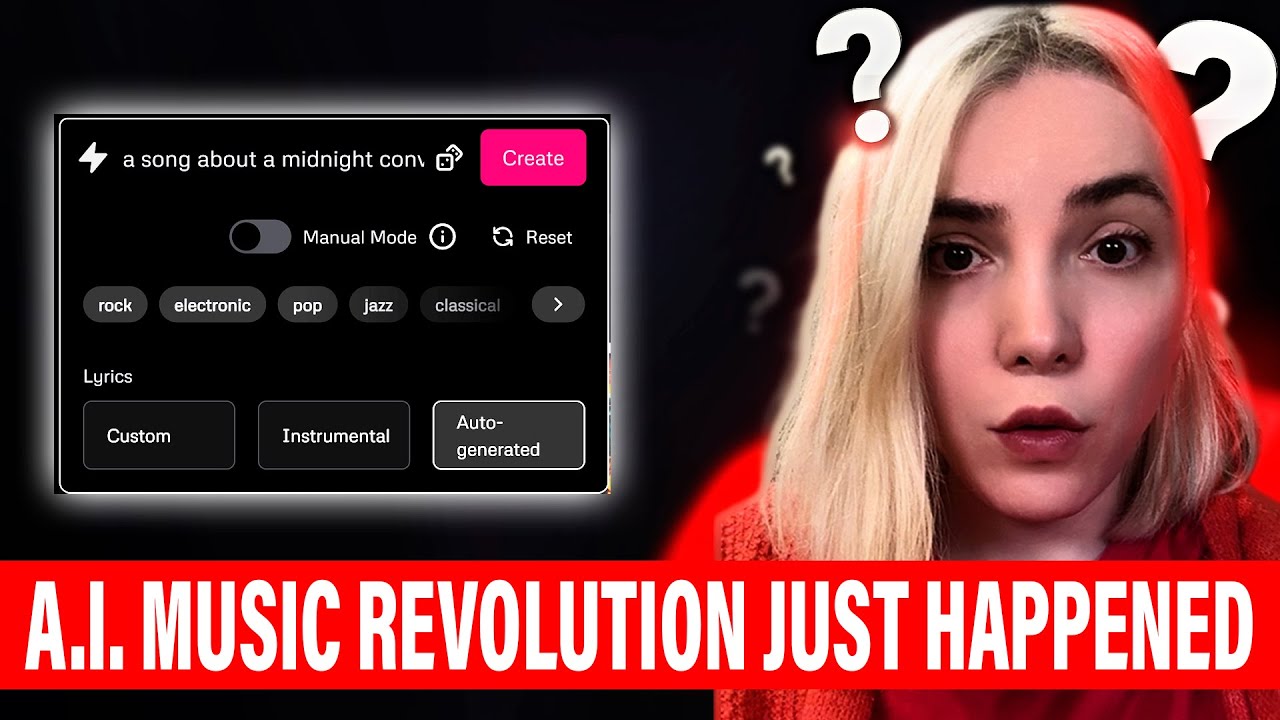 |
| For the first time, Alice Yalcin Efe is scared of AI as a music producer.
A professional music producer, been number one on BeatPort, has millions of streams on Spotify, played in big festivals and clubs, "yet for the first time I am scared of AI as a music producer." When you're homeless, you can listen to AI mix the beat on the beach. After that, she ponders what this means for all the rest of us. Those of us who aren't professional music producers. Well, I guess we can all be music producers now. "Music on demand becomes literal. You feel heartbroken, type it in. Type in the genres that you want. Type in the lyrics that you want. Type in the mood that you want and then AI spits out the perfect ballad for you to listen." "I think it's both incredible and horrifying at the same time. I honestly don't know what comes next. Will this kill the artists' soul, or will it give us just more tools to make even greater things?" |
| |
 |
| Musician Paul Folia freaks out over Suno and Udio (and other music AI). Reminds me of the freak-out of visual artists a year ago. It appears AI is going to replace humans one occupation at a time and people will freak out when it's their turn. He estimates in a year AI music will be of high enough quality to wipe out stock music writing completely, producing tracks for a price no human can compete with ($0.02 and in minutes).
He experiments with various music styles an artists' styles and the part that impressed me the most was, perhaps surprisingly, the baroque music. After noting that the training data was probably easy to get because it's public domain, he says, "This m-f-er learned some *serious* harmony. Not like three chords and some singing." |
| |
 |
| "For those who don't yet know from their other social media: a week ago the cryptographer Yilei Chen posted a preprint, eprint.iacr.org/2024/555, claiming to give a polynomial-time quantum algorithm to solve lattice problems. For example, it claims to solve the GapSVP problem, which asks to approximate the length of the shortest nonzero vector in a given n-dimensional lattice, to within an approximation ratio of ~n4.5. The best approximation ratio previously known to be achievable in classical or quantum polynomial time was exponential in n."
"If it's correct, this is an extremely big deal. It doesn't quite break the main lattice-based cryptosystems, but it would put those cryptosystems into a precarious position, vulnerable to a mere further polynomial improvement in the approximation factor. And, as we learned from the recent NIST competition, if the lattice-based and LWE-based systems were to fall, then we really don't have many great candidates left for post-quantum public-key cryptography! On top of that, a full quantum break of LWE (which, again, Chen is not claiming) would lay waste (in a world with scalable QCs, of course) to a large fraction of the beautiful sandcastles that classical and quantum cryptographers have built up over the last couple decades--everything from Fully Homomorphic Encryption schemes, to Mahadev's protocol for proving the output of any quantum computation to a classical skeptic." Wow, that's quite a lot. Let's see if we can figure out what's going on here. First of all, I hadn't heard of these "lattice" problems, but doing some digging, I found they've been of great interest to people working on quantum computers, because they're thought to be resistant to attacks from quantum computers. Quantum computers have this magical ability to use the superposition of wavefunctions to test "all combinations at once" for a mathematical problem, which could be finding a key that decrypts an encrypted message. This magical ability is harder to tap into than it sounds because, first of all, you need enough qubits (quantum bits -- the superposition bits that quantum computers use instead of the regular 0 or 1 bits of regular computers), and that's really hard because all the qubits have to be entangled, and maintaining a boatload of entangled qubits usually involves freezing atoms to near absolute zero and other such difficult things. And second of all, you have to find an algorithm -- quantum computers are not straightforward to program, and can only "run" "programs" written specifically for quantum computers, with algorithms that have been invented to solve a particular mathematical problem using quantum physics. What supposedly makes "lattice" problems harder to solve than RSA, Elliptic Curve Cryptography, and so on, is that with lattices, you can have any number of dimensions. This increase in dimensionality cranks up the number of qubits required much faster than traditional algorithms such as RSA, Elliptic Curve Cryptography, and so on. So they stand a much better chance of outpacing the advancement of quantum computers. Also, nobody has ever come up with an algorithm for cracking lattice problems... ...until now, maybe. That's what this post is about. Possibly this Yilei Chen cryptographer has found an algorithm. The specific encryption algorithm that he may have found a way to crack with a quantum computer algorithm is called GapSVP. SVP stands for "shortest vector problem" and clicking through on the link will take you to a Wikipedia page that explains the mathematics behind it. However if you scroll down in the original post you'll see there is discussion of a bug in cryptographer Yilei Chen's algorithm. It is not known whether the algorithm can be fixed or whether this means GapSVP and LWE remain unbroken. Speaking of LWE, the post also mentions LWE without giving a clue what "LWE" means. LWE stands for "Learning With Errors". In fact if you clicked through on GapSVP to the Wikipedia page, you can find a handy link to the Learning With Errors page at the bottom in the "See also" section. With LWE, you have an n-dimensional "ring" of integers -- called a "ring" instead of a "vector" because they are all modulo some prime number (remember we make this hard by making the number of dimensions and the size of the prime number huge) -- which you run through some secret linear transformation function and then perturb with some error, perhaps drawn from a Gaussian distribution. To crack the system you have to recover the secret linear transformation function. Mathematicians have proven LWE is equivalent to lattice problems and therefore is a lattice problem. The mention of Mahadev's protocol, which you can find out all about by clicking through on that link, refers to a method of verifying that a quantum algorithm works using a classical computer. The protocol works by forcing the qubits into states that are predetermined ahead of time, and then verifying those states are achieved. Of course a classical computer cannot verify the output of a quantum computer for any given input. |
| |
 |
| "AI is now dogfighting with fighter pilots in the air."
Well, that headline makes it sound like dogfighting exercises between human pilots and AI-piloted aircraft are happening now, but the article actually says, in a longwinded way, that this has been authorized and is something that should be happening soon. It has been done in simulation only so far. The AI-piloted aircraft is the X-62A, a modified two-seat F-16D that was tested last year. "The machine learning approach relies on analyzing historical data to make informed decisions for both present and future situations, often discovering insights that are imperceptible to humans or challenging to express through conventional rule-based languages. Machine learning is extraordinarily powerful in environments and situations where conditions fluctuate dynamically making it difficult to establish clear and robust rules." "Enabling a pilot-optional aircraft like the X-62A to dogfight against a real human opponent who is making unknowable independent decisions is exactly the 'environments and situations' being referred to here. Mock engagements like this can be very dangerous even for the most highly trained pilots given their unpredictability." "Trust in the ACE algorithms is set to be put to a significant test later this year when Secretary of the Air Force Frank Kendall gets into the cockpit for a test flight." "I'm going to take a ride in an autonomously flown F-16 later this year. There will be a pilot with me who will just be watching, as I will be, as the autonomous technology works, and hopefully, neither he nor I will be needed to fly the airplane." ACE stands for "Air Combat Evolution". It's a Defense Advanced Research Projects Agency (DARPA) program. Article has lots of links to more information on AI in fighter jets. |
| |
 |
| "The tiny ultrabright laser that can melt steel".
Allegedly in 2016, the Japanese government announced a plan for Society 5.0. If you're wondering what the first 4 were, they were 1: hunter/gatheres, 2: agrarian, 3: industrial, 4: the information age -- the end of which is fast approaching! Bringing us to Society 5: on-demand physical products. (Also robot caretakers, but never mind that -- you need lasers for on-demand physical products!) "The lasers of Society 5.0 will need to meet several criteria. They must be small enough to fit inside everyday devices. They must be low-cost so that the average metalworker or car buyer can afford them -- which means they must also be simple to manufacture and use energy efficiently. And because this dawning era will be about mass customization (rather than mass production), they must be highly controllable and adaptive." "Semiconductor lasers would seem the perfect candidates, except for one fatal flaw: They are much too dim." "Of course, other types of lasers can produce ultrabright beams. Carbon dioxide and fiber lasers, for instance, dominate the market for industrial applications. But compared to speck-size semiconductor lasers, they are enormous. A high-power CO2 laser can be as large as a refrigerator. They are also more expensive, less energy efficient, and harder to control." "Over the past couple of decades, our team at Kyoto University has been developing a new type of semiconductor laser that blows through the brightness ceiling of its conventional cousins. We call it the photonic-crystal surface-emitting laser, or PCSEL (pronounced 'pick-cell'). Most recently, we fabricated a PCSEL that can be as bright as gas and fiber lasers -- bright enough to quickly slice through steel -- and proposed a design for one that is 10 to 100 times as bright. Such devices could revolutionize the manufacturing and automotive industries. If we, our collaborating companies, and research groups around the world can push PCSEL brightness further still, it would even open the door to exotic applications like inertial-confinement nuclear fusion and light propulsion for spaceflight." That paragraph doesn't mention the size. 3 mm. As in, 3 millimeters. A lot smaller than a refrigerator. The rest of the article describes -- pretty decently for lay people -- how these PCSEL lasers work. "At certain wavelengths determined by the groove spacing, light refracts through and partially reflects off each interface. The overlapping reflections combine to form a standing wave that does not travel through the crystal." "In a square lattice such as that used in PCSELs, air holes bend light backward and sideways. The combination of multiple such diffractions creates a 2D standing wave. In a PCSEL, only this wave is amplified in the active layer, creating a laser beam of a single wavelength." |
| |
 |
| Sheets of gold that are one atom thick have been synthesized.
They're calling it "goldene", to make you think of "graphene," "the iconic atom-thin material made of carbon that was discovered in 2004." "Since then, scientists have identified hundreds more of these 2D materials. But it has been particularly difficult to produce 2D sheets of metals, because their atoms have always tended to cluster together to make nanoparticles instead." "Researchers have previously reported single-atom-thick layers of tin and lead stuck to various substances, and they have produced gold sheets sandwiched between other materials. But 'we submit that goldene is the first free-standing 2D metal, to the best of our knowledge', says materials scientist Lars Hultman at Linköping University in Sweden." "The Linköping researchers started with a material containing atomic monolayers of silicon sandwiched between titanium carbide. When they added gold on top of this sandwich, it diffused into the structure and exchanged places with the silicon to create a trapped atom-thick layer of gold. They then etched away the titanium carbide to release free-standing goldene sheets that were up to 100 nanometres wide, and roughly 400 times as thin as the thinnest commercial gold leaf." "That etching process used a solution of alkaline potassium ferricyanide known as Murukami's reagent. 'What's so fascinating is that it's a 100-year-old recipe used by Japanese smiths to decorate ironwork,' Hultman says. The researchers also added surfactant molecules -- compounds that formed a protective barrier between goldene and the surrounding liquid -- to stop the sheets from sticking together." "Light can generate waves in the sea of electrons at a gold nanoparticle's surface, which can channel and concentrate that energy. This strong response to light has been harnessed in gold photocatalysts to split water to produce hydrogen, for instance. Goldene could open up opportunities in areas such as this, Hultman says, but its properties need to be investigated in more detail first." |
| |
 |
| Injection molding vs 3D printing. A 2-cavity tool injection molding machine competes with 4 Form 4 3D printers in a race to make 1,000 parts, which are simple plastic latches. If it sounds a bit unfair that 1 injection molding machine goes up against 4 3D printers, they show the 3D printers cost less and take up less floor space. The also require less lead time, as in, not any, vs weeks for the injection molding machine.
See below for keynote address explaining more of how the Form 4 3D printers work. |
| |
| |
| Pulsed charging enhances the service life of lithium-ion batteries.
"Lithium-ion batteries are powerful, and they are used everywhere, from electric vehicles to electronic devices. However, their capacity gradually decreases over the course of hundreds of charging cycles. The best commercial lithium-ion batteries with electrodes made of so-called NMC532 and graphite have a service life of up to eight years. Batteries are usually charged with a constant current flow. But is this really the most favourable method? A new study by Prof Philipp Adelhelm's group at Helmholtz-Zentrum Berlin and Humboldt-University Berlin answers this question clearly with no." I skipped the chemical formula for NMC532 but it's in the article. Basically a lithium, nickel, manganese, cobalt compound. "Part of the battery tests were carried out at Aalborg University. The batteries were either charged conventionally with constant current or with a new charging protocol with pulsed current. Post-mortem analyses revealed clear differences after several charging cycles: In the constant current samples, the solid electrolyte interface at the anode was significantly thicker, which impaired the capacity. The team also found more cracks in the structure of the NMC532 and graphite electrodes, which also contributed to the loss of capacity. In contrast, pulsed current-charging led to a thinner solid electrolyte interface and fewer structural changes in the electrode materials." "Helmholtz-Zentrum Berlin researcher Dr Yaolin Xu then led the investigation into the lithium-ion cells at Humboldt University and BESSY II with operando Raman spectroscopy and dilatometry as well as X-ray absorption spectroscopy to analyse what happens during charging with different protocols. Supplementary experiments were carried out at the PETRA III synchrotron. 'The pulsed current charging promotes the homogeneous distribution of the lithium ions in the graphite and thus reduces the mechanical stress and cracking of the graphite particles. This improves the structural stability of the graphite anode,' he concludes. The pulsed charging also suppresses the structural changes of NMC532 cathode materials with less Ni-O bond length variation." BESSY stands for "Berliner Elektronenspeicherring-Gesellschaft für Synchrotronstrahlung". In English, "Berlin Electron Storage Ring Society for Synchrotron Radiation". Which would be BESRSSR. Never mind. Yes, "Electron Storage Ring" got all smashed together into "Elektronenspeicherring" in the German. "Society" seems like an odd part of the name in English. "Gesellschaft" can be translated "society" but could also be "company". Maybe "organization" would be a better word. Synchrotron radiation is a type of radiation emitted in particle accelerators when charged particles are pushed into going in circles or curved trajectories instead of being allowed to go in straight lines like they want to, and apparently requires "relativistic" speeds, which I take to mean, charged particles near the speed of light. Raman spectroscopy is a type of spectroscopy where, I'm not sure exactly how it works. You transmit a fixed wavelength of light but the vibrations of the molecules nudge the energy levels up or down such that the molecules will or won't absorb and re-emit ("scatter") the photons. Not sure how the word "dilatometry" fits into all this. "Dilatometry" just means the measurement of the amount of volume a material takes up. PETRA III is a particle accelerator in Hamburg run by DESY, the German government's national organization for fundamental physics research. DESY stands for "Deutsches Elektronen-Synchrotron" and PETRA stands for "Positron-Electron Tandem Ring Accelerator" (apparently doesn't have both German and English versions?). All in all, a pretty sophisticated amount of analysis of battery recharging. Still, the optimal frequency is not known. |
| |
 |
| "Google joins the custom server CPU crowd with Arm-based Axion chips."
"Google is the latest US cloud provider to roll its own CPUs. In fact, it's rather late to the party. Amazon's Graviton processors, which made their debut at re:Invent in 2018, are now on their fourth generation. Meanwhile, Microsoft revealed its own Arm chip, dubbed the Cobalt 100, last fall." "The search giant has a history of building custom silicon going back to 2015. However, up to this point most of its focus has been on developing faster and more capable Tensor Processing Units (TPUs) to accelerate its internal machine learning workloads." |
| |
 |
| "Airchat is a new social media app that encourages users to 'just talk.'" "Visually, Airchat should feel pretty familiar and intuitive, with the ability to follow other users, scroll through a feed of posts, then reply to, like, and share those posts. The difference is that the posts and replies are audio recordings, which the app then transcribes."
What do y'all think? You want an audio social networking app? |
| |
 |
| "One of the most common concerns about AI is the risk that it takes a meaningful portion of jobs that humans currently do, leading to major economic dislocation. Often these headlines come out of economic studies that look at various job functions and estimate the impact that AI could have on these roles, and then extrapolates the resulting labor impact. What these reports generally get wrong is the analysis is done in a vacuum, explicitly ignoring the decisions that companies actually make when presented with productivity gains introduced by a new technology -- especially given the competitive nature of most industries."
Says Aaron Levie, CEO of Box, a company that makes large-enterprise cloud file sharing and collaboration software. "Imagine you're a software company that can afford to employee 10 engineers based on your current revenue. By default, those 10 engineers produce a certain amount of output of product that you then sell to customers. If you're like almost any company on the planet, the list of things your customers want from your product far exceeds your ability to deliver those features any time soon with those 10 engineers. But the challenge, again, is that you can only afford those 10 engineers at today's revenue level. So, you decide to implement AI, and the absolute best case scenario happens: each engineer becomes magically 50% more productive. Overnight, you now have the equivalent of 15 engineers working in your company, for the previous cost of 10." "Finally, you can now build the next set of things on your product roadmap that your customers have been asking for." Read the comments, too. There is some interesting discussion, uncommon for Twitter, apparently made possible by the fact that not just Aaron Levie but some other people forked over money to Twitter to be able to post things larger than some arbitrary and super-tiny character limit. |
| |
| |
| "Evaluate LLMs in real time with Street Fighter III"
"A new kind of benchmark? Street Fighter III assesses the ability of LLMs to understand their environment and take actions based on a specific context. As opposed to RL models, which blindly take actions based on the reward function, LLMs are fully aware of the context and act accordingly." "Each player is controlled by an LLM. We send to the LLM a text description of the screen. The LLM decide on the next moves its character will make. The next moves depends on its previous moves, the moves of its opponents, its power and health bars." "Fast: It is a real time game, fast decisions are key" "Smart: A good fighter thinks 50 moves ahead" "Out of the box thinking: Outsmart your opponent with unexpected moves" "Adaptable: Learn from your mistakes and adapt your strategy" "Resilient: Keep your RPS high for an entire game" Um... Alrighty then... |
| |
 |
| "US-based startup RocketStar has successfully demonstrated an electric propulsion unit for spacecraft that uses nuclear fusion-enhanced pulsed plasma."
"By introducing boron into the thruster's exhaust, high-speed protons generated from ionized water vapor collide with boron nuclei, triggering a fusion reaction that significantly boosts the thruster's performance. This fusion process, like an afterburner in a jet engine, transforms boron into high-energy carbon, which rapidly decays into three alpha particles. The result? A remarkable 50% improvement in thrust compared to our FireStar Foundation thruster." "This discovery, initially made under an SBIR from AFWERX, has been independently validated. We've witnessed fusion reactions occur in our lab and the result is a 50% jump in thrust performance. 'RocketStar has not just incrementally improved a propulsion system, but taken a leap forward by applying a novel concept, creating a fusion-fission reaction in the exhaust! This is an exciting time in technology developments and I am looking forward to their future innovations,' stated Adam Hecht, Professor of Nuclear Engineering, University of New Mexico." "The FireStar Foundation thruster is ready to ship now. It will fly in July and October 2024 on D-Orbit's proprietary OTV ION Satellite Carrier riding on two SpaceX Transporter missions, proving performance in the ultimate test -- space itself. But get ready, because our FireStar Fusion Drive is headed to the launchpad too, scheduled for in-space testing in February 2025 on Rogue Space System's Barry-2 spacecraft." From what I've been able to figure out, and for those of you who like things expressed in equations (don't worry, for those of you scared by equations I'll describe it in words as well), what they're claiming looks like: proton + 11B -> 12C* -> 3 4He + boatload of energy Boron by definition has 5 protons, add 6 neutrons and we get the 11 isotope of boron. Hit it with a proton and that makes it 6 protons, which makes it carbon by definition. The asterisk indicates the carbon is in an "excited state", which means it has excess energy. It sheds this excess energy by splitting into 3 "alpha particles", also known as 3 helium nuclei (2 protons, 2 neutrons, without the orbiting electrons -- the "4" indicates the 4 isotope). The "boatload of energy" term of the equation increases the velocity of the thrust and cranks up the acceleration that the engine imparts to the spacecraft and the efficiency of the engine. They say, "This discovery, initially made under an SBIR from AFWERX, has been independently validated." SBIR stands for Small Business Innovation Research, a US government funding program, and AFWERX is an agency within the US Air Force for tapping into innovations from startups in the US economy. They say: "As the innovation arm of the Department of the Air Force and powered by the Air Force Research Laboratory (AFRL), AFWERX brings cutting edge American ingenuity from small businesses and start-ups to address the most pressing challenges of the Department of the Air Force." Link to their website below. I wasn't able to find any record of this on their website, but that could be because I don't know how to properly search the website. |
| |